Estimation of a single binomial or Poisson rate
To calculate a confidence interval for a single binomial proportion (), the skewness-corrected asymptotic score (SCAS) method is recommended, as one that succeeds, on average, at containing the true proportion p with the appropriate nominal probability (e.g. 95%), and has evenly distributed tail probabilities (Laud 2017, Appendix S3.5). It is a modified version of the Wilson score method. The plot below illustrates the one-sided and two-sided non-coverage probability (i.e. 1 minus the actual probability that the interval contains the true value of p) achieved by SCAS compared to some other popular methods, using moving average smoothing (solid lines):
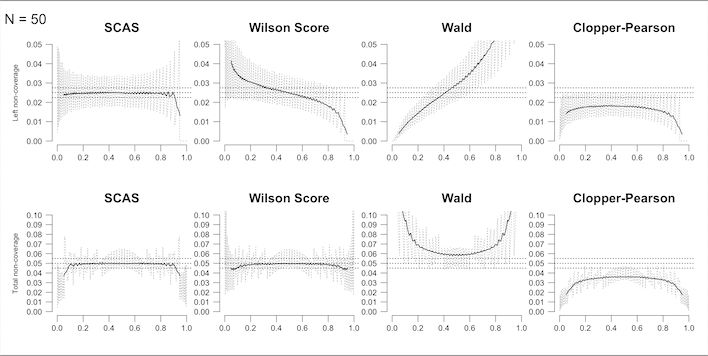
Similar patterns of coverage are seen for the corresponding methods
for a Poisson rate (Laud
2017). (Analysis for Poisson rates, such as exposure-adjusted
adverse event rates) is obtained using distrib = "poi",
with the input n representing the exposure time.)
For a worked example, the SCAS 95% interval for the binomial
proportion 1/29 is obtained with scaspci(), using
closed-form calculation (Laud 2017, Appendix A.4):
scaspci(x = 1, n = 29)
#> $estimates
#> lower est upper x n
#> [1,] 0.001991554 0.03977273 0.1548909 1 29
#>
#> $call
#> distrib level bcf cc
#> "bin" "0.95" "FALSE" "FALSE"If you prefer the slightly slower iterative calculation, or want to perform a corresponding hypothesis test, you could use:
scoreci(x1 = 1, n1 = 29, contrast = "p", precis = 4)$estimates
#> lower est upper level x1 n1 p1hat p1mle
#> [1,] 0.002 0.0398 0.1549 0.95 1 29 0.0345 0.0398rateci() also provides a number of other confidence
interval methods for reference: Jeffreys and (two versions of) mid-p
intervals have similar coverage properties to SCAS (Laud 2018), while
the Wilson, Wald and Agresti-Coull intervals are provided for comparison
but are not recommended:
rateci(x = 1, n = 29, precis = 4)$estimates
#> , , 1
#>
#> lower est upper x n
#> SCAS 0.0020 0.0345 0.1549 1 29
#> Jeffreys 0.0037 0.0345 0.1501 1 29
#> midp 0.0017 0.0345 0.1585 1 29
#> midp(beta) 0.0047 0.0345 0.1485 1 29
#> Wilson 0.0061 0.0345 0.1718 1 29
#> Wald -0.0319 0.0345 0.1009 1 29
#> Agresti-Coull -0.0084 0.0345 0.1863 1 29The Jeffreys interval can also incorporate prior information about for an approximate Bayesian confidence interval. For example, a pilot study estimate of 1/10 could be used to update the non-informative prior for to a distribution:
jeffreysci(x = 1, n = 29, ai = 1.5, bi = 9.5)
#> $estimates
#> lower est upper x n
#> [1,] 0.01080849 0.05530734 0.1544908 1 29
#>
#> $call
#> distrib level cc adj ai bi
#> "bin" "0.95" "0" "TRUE" "1.5" "9.5"If more conservative coverage is required, a continuity adjustment
may be deployed with cc, as follows, giving
continuity-adjusted SCAS or Jeffreys, and (if cc is TRUE or
0.5), the Clopper-Pearson method.
rateci(x = 1, n = 29, cc = TRUE, precis = 4)$estimates
#> , , 1
#>
#> lower est upper x n
#> SCAS_cc 0.0000 0.0345 0.1817 1 29
#> Jeffreys_cc 0.0009 0.0345 0.1776 1 29
#> Clopper-Pearson 0.0009 0.0345 0.1776 1 29
#> Clopper-Pearson(beta) 0.0009 0.0345 0.1776 1 29
#> Wilson_cc 0.0018 0.0345 0.1963 1 29
#> Wald_cc -0.0492 0.0345 0.1181 1 29
#> Blaker 0.0017 0.0345 0.1660 1 29Such an adjustment is widely acknowledged to be over-conservative, so
intermediate adjustments such as cc = 0.25 give a more
refined adjustment(Laud
2017, Appendix S2
()).
rateci(x = 1, n = 29, cc = 0.25, precis = 4)$estimates
#> , , 1
#>
#> lower est upper x n
#> SCAS_cc(0.25) 0.0006 0.0345 0.1685 1 29
#> Jeffreys_cc(0.25) 0.0021 0.0345 0.1641 1 29
#> midp_cc(0.25) 0.0012 0.0345 0.1694 1 29
#> midp(beta)_cc(0.25) 0.0028 0.0345 0.1631 1 29
#> Wilson_cc(0.25) 0.0038 0.0345 0.1841 1 29
#> Wald_cc(0.25) -0.0405 0.0345 0.1095 1 29Stratified datasets
For stratified datasets (e.g. data collected in different subgroups
or collated across different studies), use scoreci() with
contrast = "p" and stratified = TRUE (again,
the skewness correction is recommended, but may be omitted for a
stratified Wilson interval).
By default, a fixed effect analysis is produced, i.e. one which
assumes a common true parameter p across strata. The default stratum
weighting uses the inverse variance of the score underlying the
SCAS/Wilson method, evaluated at the maximum likelihood estimate for the
pooled proportion (thus avoiding infinite weights for boundary cases).
Alternative weights are sample size (weighting = "MH") or
custom user-specified weights supplied via the wt argument.
For example, population weighting would be applied via a vector
(e.g. wt = Ni) containing the true population size
represented by each stratum. (Note this is not divided by the sample
size per stratum, because the weighting is applied at the group level,
not the case level.)
Below is an illustration using control arm data from a meta-analysis of 9 trials studying postoperative deep vein thrombosis (DVT). This may be a somewhat unrealistic example, as the main focus of these studies is to estimate the effect of a treatment, rather than to estimate the underlying risk of an event.
data(compress, package = "ratesci")
strat_p <- scoreci(x1 = compress$event.control,
n1 = compress$n.control,
contrast = "p",
stratified = TRUE,
precis = 4)
strat_p$estimates
#> lower est upper level p1hat p1mle
#> [1,] 0.1815 0.2123 0.2454 0.95 0.2121 0.2123The function also outputs p-values for a two-sided hypothesis test against a default null hypothesis p = 0.5, and one-sided tests against a user-specified value of :
strat_p$pval
#> chisq pval2sided theta0 scorenull pval_left pval_right
#> [1,] 207.8485 4.048337e-47 0.5 -14.41695 2.024169e-47 1The Qtest output object provides a heterogeneity test
and related quantities. In this instance, there appears to be
significant variability between studies in the underlying event rate for
the control group, which may reflect different characteristics of the
populations in each study leading to different underlying risk. (Note
this need not prevent the evaluation of stratified treatment
comparisons):
strat_p$Qtest
#> Q Q_df pval_het I2 tau2 Qc
#> 6.367071e+01 8.000000e+00 8.834566e-11 8.743535e+01 1.739866e-02 0.000000e+00
#> pval_qualhet
#> 9.960938e-01Per-stratum estimates are produced, including stratum weights and contributions to the Q-statistic. Here the studies contributing most are the 3rd and 8th study, with estimated proportions of 0.48 (95% CI: 0.34 to 0.62) and 0.04 (95% CI: 0.01 to 0.10) respectively:
strat_p$stratdata
#> x1j n1j p1hatj wt_fixed wtpct_fixed wtpct_rand theta_j lower_j upper_j
#> [1,] 37 103 0.3592 615.9809 16.4274 16.4274 0.3597 0.2713 0.4550
#> [2,] 5 10 0.5000 59.8040 1.5949 1.5949 0.5000 0.2175 0.7825
#> [3,] 23 48 0.4792 287.0591 7.6555 7.6555 0.4793 0.3419 0.6189
#> [4,] 16 110 0.1455 657.8437 17.5439 17.5439 0.1465 0.0888 0.2205
#> [5,] 7 32 0.2188 191.3727 5.1037 5.1037 0.2216 0.1021 0.3838
#> [6,] 8 25 0.3200 149.5099 3.9872 3.9872 0.3224 0.1626 0.5165
#> [7,] 17 126 0.1349 753.5301 20.0957 20.0957 0.1359 0.0835 0.2029
#> [8,] 4 92 0.0435 550.1966 14.6730 14.6730 0.0451 0.0143 0.1009
#> [9,] 16 81 0.1975 484.4122 12.9187 12.9187 0.1988 0.1219 0.2944
#> V_j Stheta_j Q_j
#> [1,] 0.0016 0.1470 13.3018
#> [2,] 0.0167 0.2877 4.9510
#> [3,] 0.0035 0.2669 20.4479
#> [4,] 0.0015 -0.0668 2.9370
#> [5,] 0.0052 0.0065 0.0080
#> [6,] 0.0067 0.1077 1.7351
#> [7,] 0.0013 -0.0774 4.5086
#> [8,] 0.0018 -0.1688 15.6759
#> [9,] 0.0021 -0.0147 0.1053For a random effects analysis, use random = TRUE. (This
may not give a meaningful estimate of stratum variation if the number of
strata is small.)
strat_p_rand <- scoreci(x1 = compress$event.control,
n1 = compress$n.control,
contrast = "p",
stratified = TRUE,
random = TRUE,
prediction = TRUE,
precis = 4)
strat_p_rand$estimates
#> lower est upper level p1hat p1mle
#> [1,] 0.136 0.2498 0.3639 0.95 0.2498 0.2498
strat_p_rand$pval
#> chisq pval2sided theta0 scorenull pval_left pval_right
#> [1,] 25.23654 0.001022283 0.5 -5.023598 0.0005111417 0.9994889A prediction interval, representing an expected proportion in a new
study (Higgins et al.
2008), can be obtained using
prediction = TRUE:
strat_p_rand$prediction
#> lower upper
#> [1,] 0 0.5705Clustered datasets
For clustered data, use clusterpci(), which applies the
Wilson-based method proposed by (Saha et al. 2015), and a
skewness-corrected version. (This function currently only applies for
binomial proportions.)
# Data from Liang 1992
x <- c(rep(c(0, 1), c(36, 12)),
rep(c(0, 1, 2), c(15, 7, 1)),
rep(c(0, 1, 2, 3), c(5, 7, 3, 2)),
rep(c(0, 1, 2), c(3, 3, 1)),
c(0, 2, 3, 4, 6))
n <- c(rep(1, 48),
rep(2, 23),
rep(3, 17),
rep(4, 7),
rep(6, 5))
# Wilson-based interval as per Saha et al.
clusterpci(x, n, skew = FALSE)$estimates
#> lower est upper totx totn xihat icc
#> [1,] 0.2285 0.2956 0.3728 60 203 1.349 0.1855
# Skewness-corrected version
clusterpci(x, n, skew = TRUE)$estimates
#> lower est upper x n totx totn xihat icc
#> [1,] 0.2276 0.2958 0.3724 60 203 60 203 1.349 0.1855Technical details
The SCAS method is an extension of the Wilson score method, using the same score function , where is the observed number of events from trials, and is the true proportion. The variance of is , and the 3rd central moment is . The confidence interval is found as the two solutions (solving for p) of the following equation, where is the percentile of the standard normal distribution:
For unstratified datasets, this has a closed-form solution. The formula is extended in (Laud 2017) to incorporate stratification using inverse variance weights, , or sample size, , or any other weighting scheme as required, with the solution being found by iteration over .
The hypothesis tests are based on the same equation, but solving to find the value of the test statistic z for the given null proportion p.
The Jeffreys interval is obtained as and quantiles of the distribution, with boundary modifications when or (Brown et al. 2001).
A Clopper-Pearson interval may also be obtained as quantiles of a beta distribution (Brown et al. 2001), using for the lower confidence limit, and for the upper limit.